大数据可视化技术调研报告
功能需求(拟定)
- 实时监控并展示服务器中的Hadoop集群运行状况,包括节点进程的运行与通信日志(报错的捕捉与报警)、存储空间的变化、配置文件信息等。
- 数据信息的图形化展示,展示数据库与数据表的信息(比如),
- 交互式的数据分析,封装好一些常用的SQL查询,能够在图形化界面操作直接展示表格与图形结果;封装一些数据分析算法并提供数据输入和参数设定的接口,能根据不同的数据源和参数选择实时运行出不同的实验结果。
- 提供自定义代码入口,在以后的研究中可以随时添加尚未封装进去的新的数据分析功能。
大数据VS传统可视化
面向的数据对象:大数据可视化工具必须能够处理半结构化和非结构化数据(大数据通常具有这种格式)
维度选择:需要做到精确,如果减小维度以使可视化程度降低,则可能最终会丢失有用的模式,但是如果使用所有维度,最终可能会导致可视化过于密集而无法用于可视化。
实时性:必须适应大数据的爆炸式增长需求,必须快速地收集分析数据、并对数据信息进行实时更新。
多种数据集成支持方式:大数据的数据来源不仅仅局限于数据库,数据可视化工具需要能够支持团队协作数据、数据仓库、文本等多种方式,并能够通过互联网进行展现。
数据可视化工具
汇总
| 开源工具 | 商业工具 |
|---|---|
| Processing | Tableau |
| Many Eyes | Spotfire(TIBCO) |
| D3.js | QlikView |
| R(基础包、lattice、ggplot2) | FineBI |
| ECharts | SAS Visual Analytics |
| Google Charts | Adobe Illustrator |
| Flot | HighCharts |
| Gephi | iCharts |
| Envision.js | Jolicharts |
| Prefuse | Dundas Chart |
| Arbor.js | LightningChart |
| Chart.js | Microsoft Excel |
| Paper.js | |
| NodeBox |
部分开源工具
D3.js
优点:免费的JavaScript库,可以将任意数据连接到HTML的文档对象模型(DOM),然后将数据驱动的转换应用于文档,通过DOM编程API可以将文档作为对象访问。支持用于交互和动画的大型数据集和动态行为,开发时可以通过浏览器的内置元素检查器进行调试。
缺点:入门需要花费的时间较多
适用于擅长JavaScript,SVG或DOM的开发人员。
plotly
优点:用于创建图表和基于浏览器的开源Python图形库。可称为高级图表库,因为它是内置于D3.js库的顶部。可以使用该工具通过上载CSV文件或连接到SQL数据库来创建D3.js图表和地图。导出图片的质量较高,图形界面完全交互式。Plotly可以提供比较少见的图表,比如等高线图、烛台图(K线图)和3D图表,而大多数工具都没有这些图表。此外,Plotly的团队还维护着增长飞快的R、Python以及JavaScript的开源可视化库。
缺点:它不涉及jQuery,仅限于原始的JavaScript,需要API密钥和注册而不是pip安装。
适用于擅长Python的开发人员
RawGraphs
优点:目标是构建电子表格和矢量图形编辑器之间的链接,可以可视化TSV,CSV,DSV或JSON数据,有助于将数据转换为图表。数据导入的过程像复制粘贴一样简单,上传到RAW的数据将仅由Web浏览器处理,保证数据安全。
缺点:大多数图表的目的不明确(没有基本的线条图),需要开发人员来开发自定义图表。
Candela
带有一个标准化API,可用于实际数据科学应用程序,并且可以通过Resonant平台使用。
Sigmajs
Sigmajs是一个交互式可视化JavaScript函数库,专门用于制作关系网络图。Sigmajs可以在网页上显示社交关系脉络,在大数据社交网络可视化中非常重要。Sigmajs还支持展示从Gephi导出的图表,可以使用Sigmajs将这些图表直接展示在网页上。
AntV
是蚂蚁集团研发的一个可视化控件解决方案,包括了可视化图形语法、可视化引擎、图分析工具和地理空间数据的可视化框架等。从它的官网可以了解到现在阿里系的产品(支付宝、淘宝等)里的可视化都基于AntV开发。
ECharts
基于Canvas的纯Javascript的图表库,提供直观、生动、可交互、可个性化定制的数据可视化图表。ECharts 提供了常规的折线图、柱状图、散点图、饼图、K线图,用于统计的盒形图,用于地理数据可视化的地图、热力图、线图,用于关系数据可视化的关系图、treemap、旭日图,多维数据可视化的平行坐标,还有用于 BI 的漏斗图,仪表盘,并且支持图与图之间的混搭。并且有深度的交互式数据探索,可以对数据进行多维度数据筛取、视图缩放、展示细节等交互操作。与D3.js相比,ECharts由百度团队研发,中文文档比较清晰,相对来说上手难度更低一点。
D3.js与ECharts的对比
这两个工具是目前各大公司的大数据平台最流行使用的图形库。
D3.js(基于SVG)
太底层,学习成本大
兼容到IE9以上以及所有的主流浏览器
D3.js通过svg来绘制图形
可以自定义事件
SVG:不依赖分辨率;基于xml绘制图形,可以操作dom;支持事件处理器;但复杂度高,会减慢页面的渲染速度。
ECharts(基于canvas)
- 封装好的方法直接调用
- 兼容到ie6以及以上的所有主流浏览器
- echarts通过canvas来绘制图形
- 封装好的,直接用,不能修改
- canvas:依赖分辨率;基于js绘制图形;不支持事件处理器;能以png或者jpg的格式保存图片
总结
一般的数据交互,后台返回数据,前端将数据通过图表的形式展示给用户,对于这种只是展示数据的话较常用的是ECharts。而像一些鼠标、键盘、触屏事件操作的话,是用D3.js实现的。
部分互联网公司的商用产品
RayData
腾讯开发的大数据可视交互系统,核心技术基于Ventuz开发。
Sugar
百度开发的自助BI报表分析和制作可视化数据大屏的强大工具,组件丰富,无需SQL和任何编码。
DataV
阿里开发的用于实时数据大屏追踪业务全貌的可视化产品,属于拖拽式可视化工具,专精于业务数据与地理信息融合的大数据可视化。核心技术采用了Blink(是阿里巴巴内部的Apache Flink版本代号)。在GitHub上有同款的开源的Vue数据可视化组件库。
网易有数
网易研发的面向企业客户的可视化敏捷BI产品,在网易系产品里有使用。
FineBI
技术架构:
Java开发
后端:spring mvc + Hibernate
前端:fineui
适用范围
- 开发/数据人员准备好数据,数据人员/业务人员分析。
- 业务人员完全可自行分析、制作可视化。整个数据分析流程分工明确。
可视化水平
- 支持的图表类型多,达47种
- 图表可视化选项少,例如,数据格式选项偏少,如需添加,需要修改配置文件
- 可在看板中添加筛选框,支持在不同条件下查看
- 不支持图表和看板分组管理
- 没有提供图表的下钻功能,不支持多图表间的复杂联动
- 不支持跨库的表关联查询
对比
互联网公司的商用产品均大同小异,均有常用的图表和地理信息图。
百度的Sugar提供的行业模板很少,支持的数据源类型较少,尤其不支持静态数据,不方便调试;操作的便捷性上有很多细节需要完善,如不支持元素多选、对齐等操作,无法去掉表格的表头等。在3D方面尚有不足,没有阿里云DataV、腾讯RayData的3D效果突出,但是有ECharts的加持,报表渲染比较流畅。
阿里的DataV常用于数据大屏展示,若没有这个方面需求的话该优势可以忽略。相比之下RayData的大屏产品能力较弱,但有原厂服务+框架服务,优势在于三维城市场景方面。
基于Hadoop的开源可视化项目
Superset
Apache系列里的基于web的开源BI工具,基于python开发的,所以也算是python生态的一员。它的三大特点是:开源、轻量级、图表丰富,需要在网页上创建看板,然后在看板中创建图表,支持连接SQL查询结果来实时展示图形化结果。
数据库支持
Superset 是基于 Druid.io 设计的,但是又支持横向到像 SQLAlchemy 这样的常见Python ORM框架上面。
Druid 是一个基于分布式的快速列式存储,也是一个为BI设计的开源数据存储查询工具。Druid提供了一种实时数据低延迟的插入、灵活的数据探索和快速数据聚合。现有的Druid已经可以支持扩展到TB级别的事件和PB级的数据了,Druid是BI应用的最佳搭档。跟类似产品Hive相比,速度快了很多。
在数据源上:支持各种数据源,包括Hive、Kylin等。
产品结构
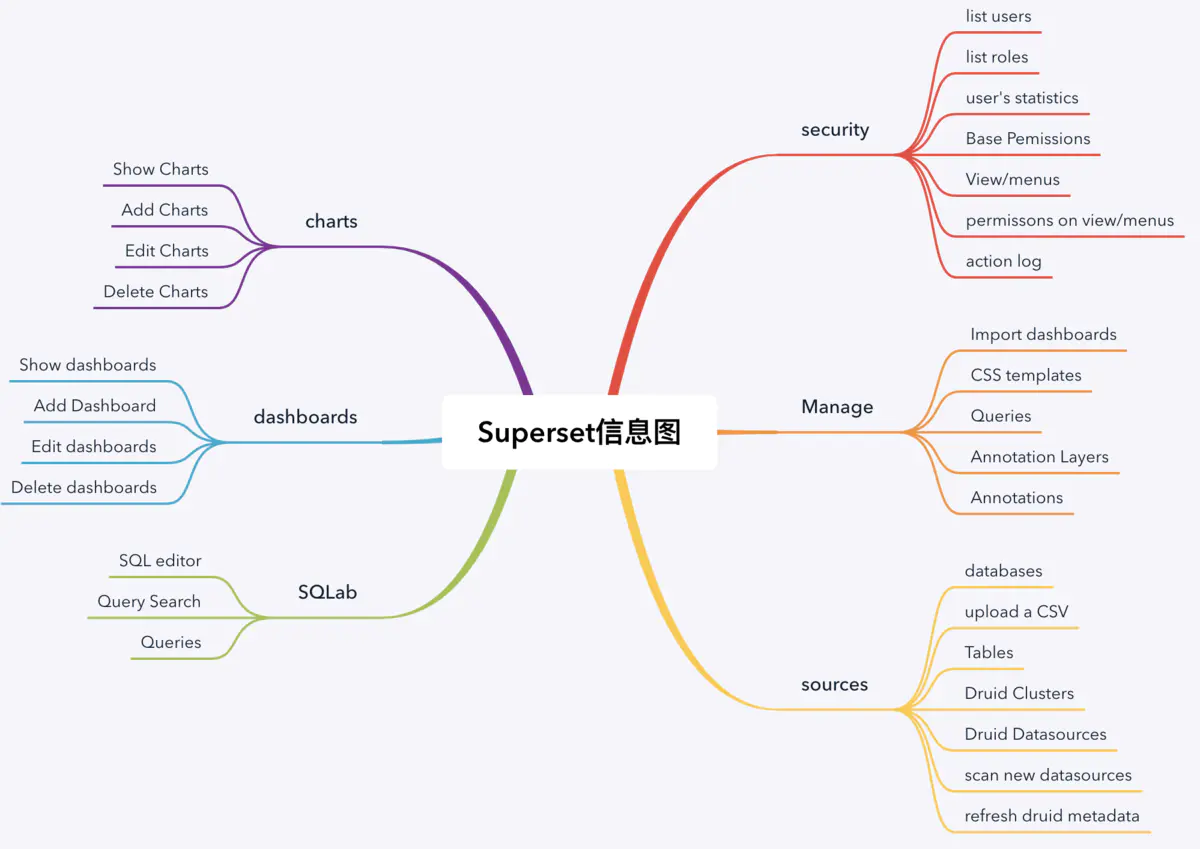
开发架构
整个项目的后端是基于Python的,用到了Flask、Pandas、SqlAlchemy。
后端
- Flask App Builder(鉴权、CRUD、规则)
- Pandas(分析)
- SqlAlchemy(数据库ORM)
前端
- 借助 FAB 来生成大部分管理界面,而图表或是 SQL 编辑器等对交互性要求很高的界面,则由 React + Redux 来实现
- Web 服务器是一个标准的 WSGI 应用
- 用到了npm、react、webpack,意味着可以在手机也可以流畅使用。
- D3.js(数据可视化)
- nvd3.org(可重用图表)
局限性
- Superset的可视化目前只支持每次可视化一张表,对于多表join的情况还无能为力
- 依赖于数据库的快速响应,如果数据库本身太慢Superset也没什么办法
- 语义层的封装还需要完善,因为druid原生只支持部分SQL
- 页面样式简单,页面的灵活度不高,不能实现二级联动,调用api接口
可视化水平
- 支持的图表类型多,达47种
- 图表可视化选项少,例如,数据格式选项偏少,如需添加,需要修改配置文件
- 可在看板中添加筛选框,支持在不同条件下查看
- 不支持图表和看板分组管理
- 没有提供图表的下钻功能,不支持多图表间的复杂联动
- 不支持跨库的表关联查询
- 支持其他图标库扩展
支持文档
- 安装部署和快速入门方面的文档详细
- 但具体功能和图表制作方面的介绍文档需要搜索资料
- 整体文档资料相当简陋
适用范围
- 开发/分析人员做好看板,业务人员浏览看板数据
- 业务人员可自行编辑图表,查看满足条件的结果
参考
解密Airbnb 自助BI神器:Superset 颠覆 Tableau
Metabase
metabase是一款易用、开源、技术成熟、不断并快速迭代的报表系统。使用metabase可以省去很多前后端的开发工作,只需要进行数据清洗计算转存等相关开发。在目前无开发人力的情况下,这是较为完美的BI系统解决方案。适合查看运行数据,业务人员自己就可以做数据分析。
开发架构
前端
React + Redux等相关框架写的单页应用,基于yarn的开发环境,webpack构建,加上D3.js作图。
后端
Clojure + RING(中间件) + Compojure(路由框架) + Toucan(ORM框架)
数据源
支持数据源少(12种),不支持Hive、Kylin(硬伤)
可视化水平
- 支持的图表类型不如Superset多,仅14种
- 图表可视化选项多,例如,提供数据格式多,设置灵活
- 可在看板中添加筛选框,支持在不同条件下查看
- 通过创建集合,支持图表、看板、定时任务分组管理
- 提供图表的简单钻取功能,不支持图表间的复杂联动
- 不支持跨库的表关联查询
适用范围
界面漂亮、友好,使用体验好,适合业务人员使用。
用户评价
Metabase 的系统切分与模块化做得非常出色,在前端架构方面 Metabase 较为占优。
提供完整 API 文档的项目,这使得开发者即使完全不会 Clojure,依然可以凭借丰富的 API 与文档完成许多二次开发。
部署方面,Metabase 提供了 Jar 文件,Mac 应用程序,Docker 镜像等方式可以让使用者在本地快速尝试该项目。而在生产环境中,它提供了如何在 AWS、Heroku、Kubernetes 上部署的详尽文档,资料较为完善。
参考
Metabase-BI系列01:二次开发环境(windows)搭建
Redash
开发架构
官方文档里的原话是:Redash采用最新的React和Python Flask技术开发,要求开发人员具备React和Python Flask基础;另外由于后台查询运行在RQ异步队列之上,开发人员必须对RQ和Redis有所了解;OLAP采用的是Postgresql分析型数据库;另外对于开发工具,前端React基本都采用VSCODE,后端可以选择VSCODE或PyCharm,开发人员必须对这些IDE有一定的了解。
后端
后端逻辑:
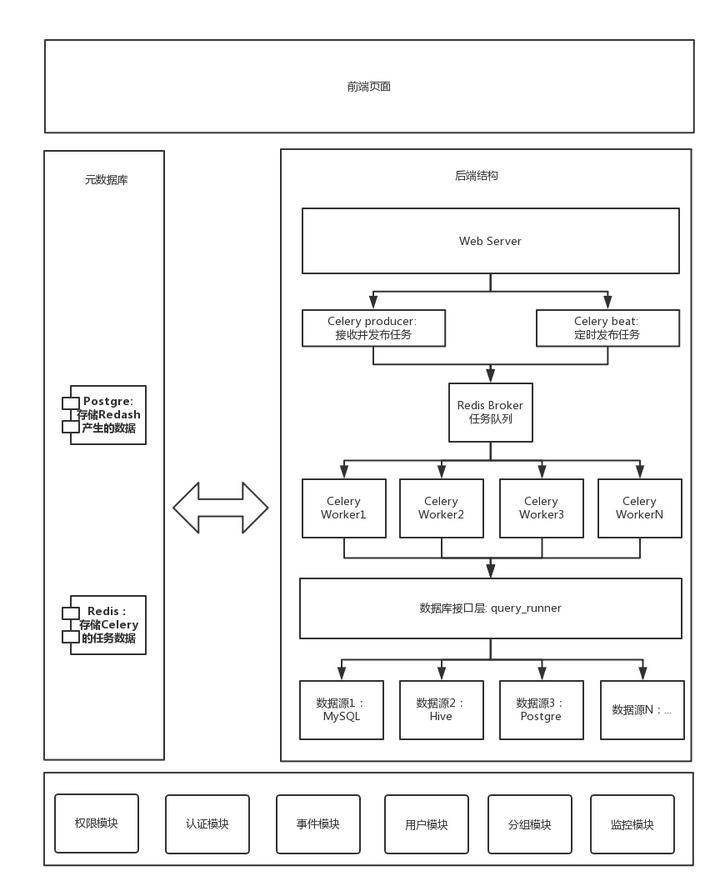
Redash 的服务器端是用 Python 来写的,Web 框架以 Flask 为基础,并充分利用了 Flask 的插件生态圈,主要用了以下的组件:
- API 框架:Flask-RESTful
- 数据库:Flask-SQLAlchemy
- 认证:Flask-Login
前端
Redash 的前端是一个纯的单页应用,用 AngularJS(1.5)实现,结构清晰,代码整洁。但众所周知,AngularJS 在 v2 之后做了巨大的架构调整,所以 AngularJS v1的处境就有些尴尬。这和目前 Python 2 的处境类似。短期内不会有问题,长期来讲是个隐患。
数据源
支持数据源比Superset少,不支持Kylin
可视化水平
- 支持的图表类型不如Superset多,仅12种
- 图表可视化选项多
- 不支持在看板种添加筛选框
- 不支持图表和看板分组管理
- 没有提供图表的下钻功能,不支持多图表间的复杂联动
- 不支持跨库的表关联查询
适用范围
由于是对SQL查询结果进行可视化,需要开发/分析人员做好看板,业务人员浏览看板数据。
技术架构:Python + Flask + AngularJS + SQLAlchemy
参考
Zeppelin
支持数据驱动、交互式数据分析、协作式文档等特性的基于Web的交互式应用开发引擎,应用以Notebook形式表示,支持Scala、Python、SQL、Markdown、shell等多种语言。严格意义上说,Zeppelin更像是一notebook,而不是一个单纯的BI工具,来自Apache项目。
开发技术架构
交互式数据分析开源框架,支持多种语言, 包括Scala、Python、SparkSQL、Hive、Markdown、Shell等
适用范围
更适合开发人员
可视化
不支持sql查询
可视化思路总结
- 可以根据开源项目直接进行二次开发,或者仿照开源项目的源码结构自行搭建。
- 在开源工具基础上自制工具需要先决定整个页面展现的形式,建议基于一个后台管理系统型界面,加入用户权限管理。
- Hadoop集群运行状况页面:可以采用HUE里的框架,集成服务器里的Hadoop进程的运行状态,在同一个页面里展示。
- 数据信息的图形化展示页面:参考vue-big-screen里集成DataV的思路,采用ECharts工具,把生成的图表展示到VUE的一个页面里。
- 交互式的数据分析页面:参考Superset里把SQL查询结果图形化的思路,设定调用SQL的时间间隔并持续更新展示在前端的图表。
- 自定义代码的功能输入页面:设定一个统一的代码格式,规定输入为xxx数据源,输出为xxx格式的数据表或其他数据结构,在系统中开设一个自定义函数入口。
参考
- 20 free and open source data visualization tools
- Top 20 Best Data Visualization Software in 2021: Free and Commercial
- 专利:大数据可视化交互系统
- 基于Hadoop和Django的大数据可视化分析Web系统
- 基于Hadoop的数据可视化技术研究与应用
- 基于Hadoop和D3.JS的互联网+博物馆可视化平台的研究与实现
- 基于hadoop的网站用户行为分析系统设计与实现
- The Trend, Hotspots, Frontier and Path of Big Data Visualization Research in China——Based on the Knowledge Graph Analysis of Citespace5.5.R2
- Big data visualization: Tools and challenges
- 数据可视化的开源方案: Superset vs Redash vs Metabase
- BI、数据可视化工具浅析整理