《大数据技术原理与应用》学习笔记——Ch3:分布式文件系统HDFS
Intro
本文为《大数据技术原理与应用》第三章学习笔记。
HDFS编程实践参考教程
HDFS简介
Hadoop分布式文件系统(Hadoop Distributed File System,HDFS),大数据平台两大核心技术之一,为了解决海量数据的分布式存储问题。
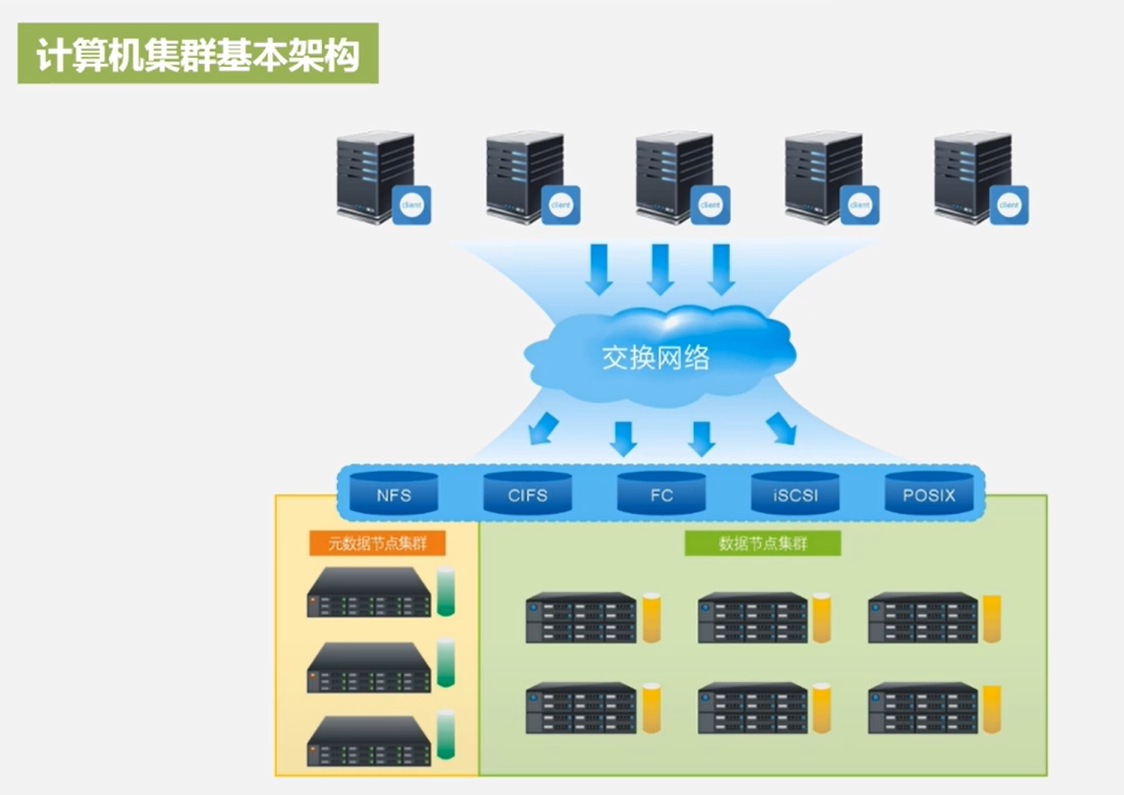
计算机集群结构
分布式文件系统的结构
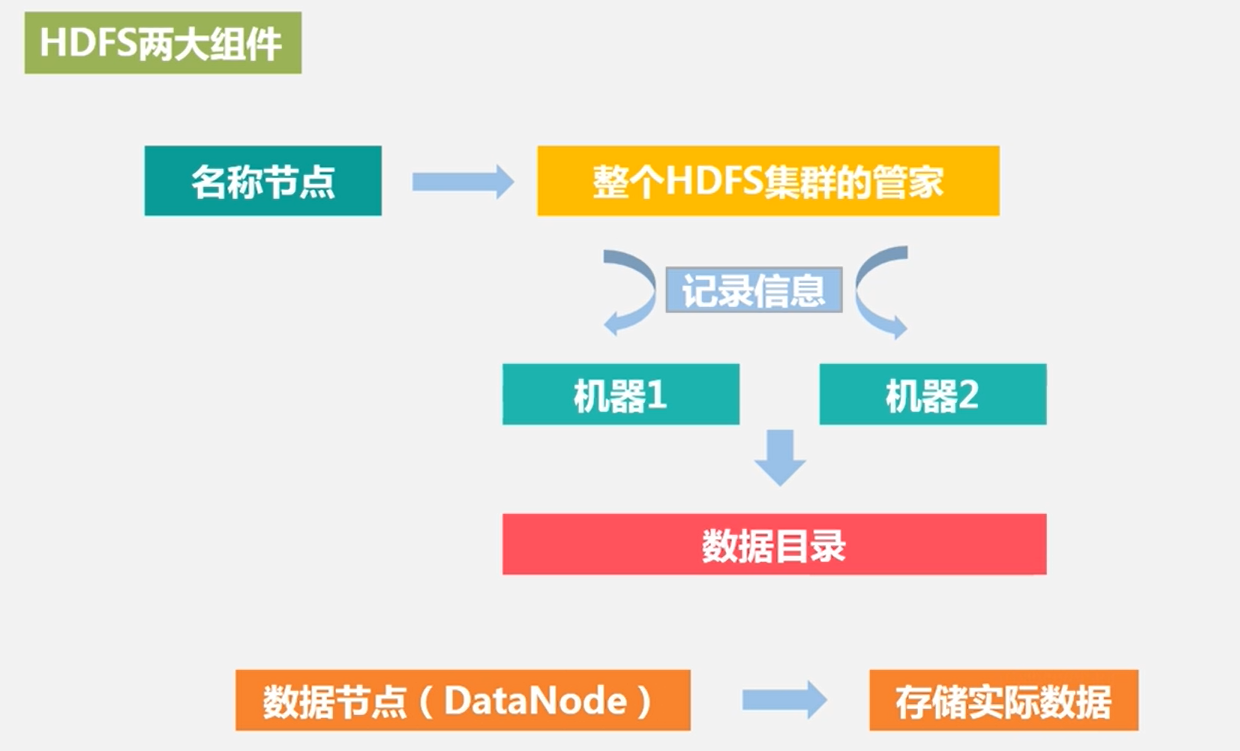
分布式文件系统在物理结构上是由计算机集群中的多个节点构成的,这些节点分为两类,一类叫“主节点”(Master Node)或者也被称为“名称结点”(NameNode),另 一类叫“从节点”(Slave Node)或者也被称为“数据节点”(DataNode)。
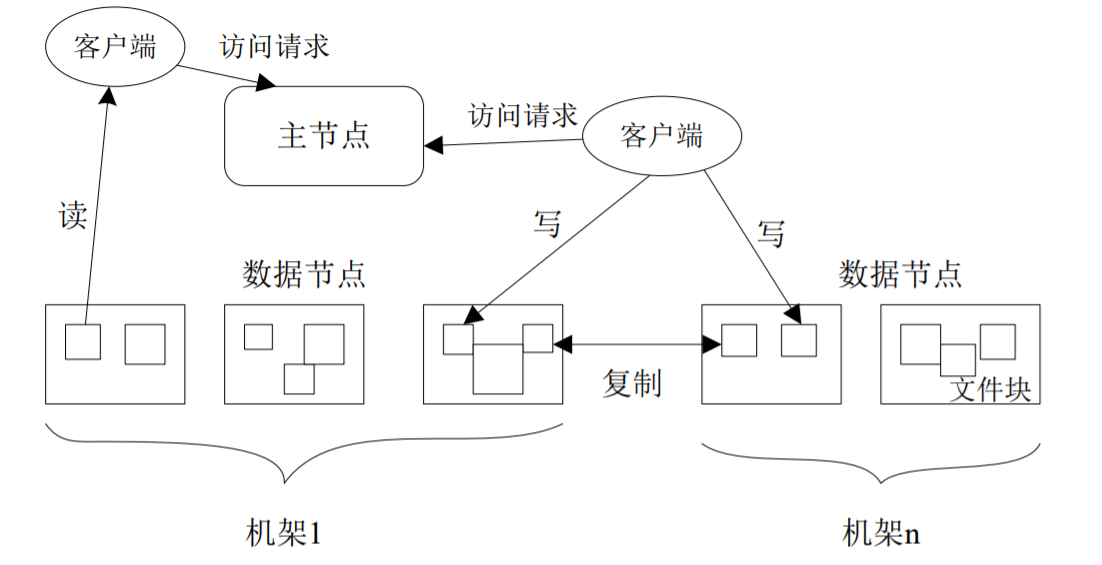
主节点:数据目录(元数据)服务。负责文件和目录的创建、删除和重命名等,同时管理数据节点和文件块的映射关系。
从节点:完成数据存储任务。负责数据的存储和读取。
- 存储:由NameNode分配存储位置,然后由客户端把数据直接写入相应DataNode。
- 读取:客户端从NameNode中获得数据节点和文件块的映射关系,然后到相应位置访问文件块。
通常采用多副本存储:文件块被复制为多个副本存储在不同节点上,且存储同一文件块的不同副本的各个节点分布在不同机架上。
HDFS实现目标:
兼容廉价的硬件设备
流数据读写
大数据集
简单的文件模型
强大的跨平台兼容性
局限性:
- 不适合低延迟数据访问(高吞吐率、高延迟,低时延需要用到HBase)
- 无法高效存储大量小文件(大小小于一个块的文件)
- 不支持多用户写入及任意修改文件(一个文件只允许一个写入者,对文件仅允许追加操作)
HDFS的相关概念
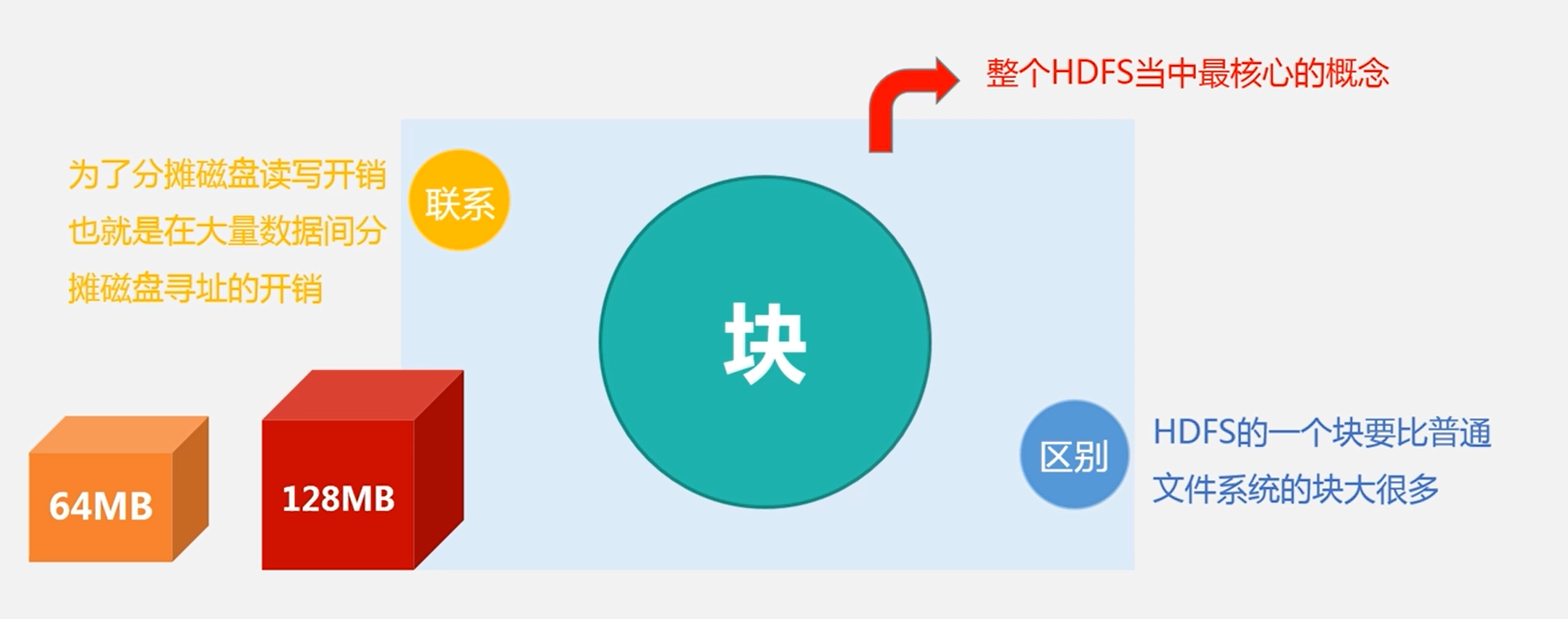
块
HDFS默认一个块64MB,一个文件被分成多个块,以块作为存储单位
设计目的:
支持面向大规模数据存储
降低分布式节点的寻址开销
缺点:块过大会牺牲MapReduce的并行度
HDFS采用抽象的块概念的好处:
- 支持大规模文件存储
- 简化系统设计
- 适合数据备份
名称节点和数据节点
| NameNode | DataNode |
|---|---|
| 存储元数据 | 存储文件内容 |
| 元数据保存在内存中 | 文件内容保存在磁盘中 |
| 保存文件,block,datanode之间的映射关系 | 维护了block id到datanode本地文件的映射关系 |
NameNode记录的元数据记录的信息(数据目录的作用):
- 文件是什么
- 文件被分成多少块
- 每个块和文件是怎么映射的
- 每个块被存储在哪个服务器上面
NameNode的数据结构
两个核心的数据结构:
- FsImage:包含文件系统中所有目录和文件inode的序列化形式。每个inode是一 个文件或目录的元数据的内部表示,并包含此类信息:文件的复制等级、修改和访问时间、访问权限、块大小以及组成文件的块。(FsImage文件没有记录块存储在哪个数据节点。而是由名称节点把这些映射保留在内存中,当数据节点加入HDFS集群时,数据节点会把自己所包含的块列表告知给名称节点,此后会定期执行这种告知操作,以确保名称节点的块映射是最新的。)
- EditLog:记录所有针对文件的创建、删除、重命名等操作。
NameNode的启动
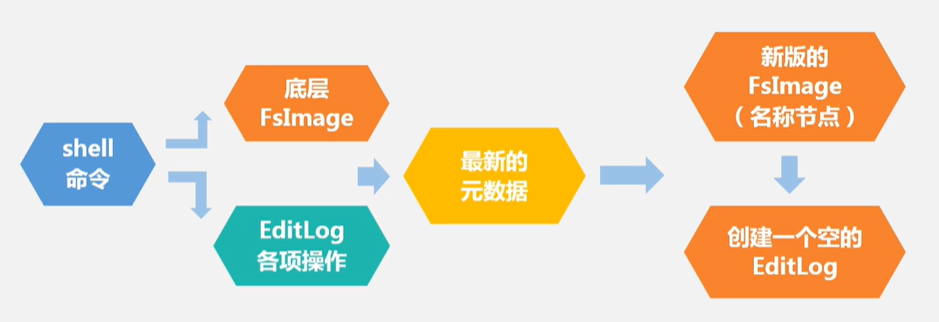
- 在名称节点启动的时候,它会将FsImage文件中的内容加载到内存中,之后再执行EditLog文件中的各项操作,使得内存中的元数据和实际的同步,保持最新,存在内存中的元数据支持客户端的读操作。
- 一旦在内存中成功建立文件系统元数据的映射,则创建一个新的FsImage文件和一个空的EditLog文件。
- (为什么不只用一个FsImage的原因)名称节点启动之后,HDFS中的更新操作会重新写到EditLog文件中,因为FsImage文件一般都很大(GB级别的很常见),如果所有的更新操作都往FsImage文件中添加,这样会导致系统运行的十分缓慢,但是,如果往EditLog文件里面写就不会这样,因为EditLog 要小很多。每次执行写操作之后,且在向客户端发送成功代码之前,edits文件都需要同步更新。
- NameNode在启动过程中会处于“安全模式”,只能对外提供读操作,无法提供写操作。启动过程结束后,系统退出安全模式。
SecondaryNameNode(第二名称节点)
解决名称节点运行期间EditLog不断变大的问题:对名称节点运行时候是没有什么明显影响的,但是当名称节点重启的时候,名称节点需要先将FsImage里面的所有内容映像到内存中,然后再一条一条地执行EditLog中的记录,当 EditLog文件非常大的时候,会导致名称节点启动操作非常慢。
SecondaryNameNode:用来保存名称节点中对HDFS元数据信息的冷备份,并减少名称节点重启的时间,一般单独运行在一台机器上。
功能:
- 完成EditLog和FsImage的合并操作,减少EditLog文件大小,缩短NameNode重启时间;
- 作为NameNode的“检查点”,保存NameNode中的元数据信息。
工作机制:
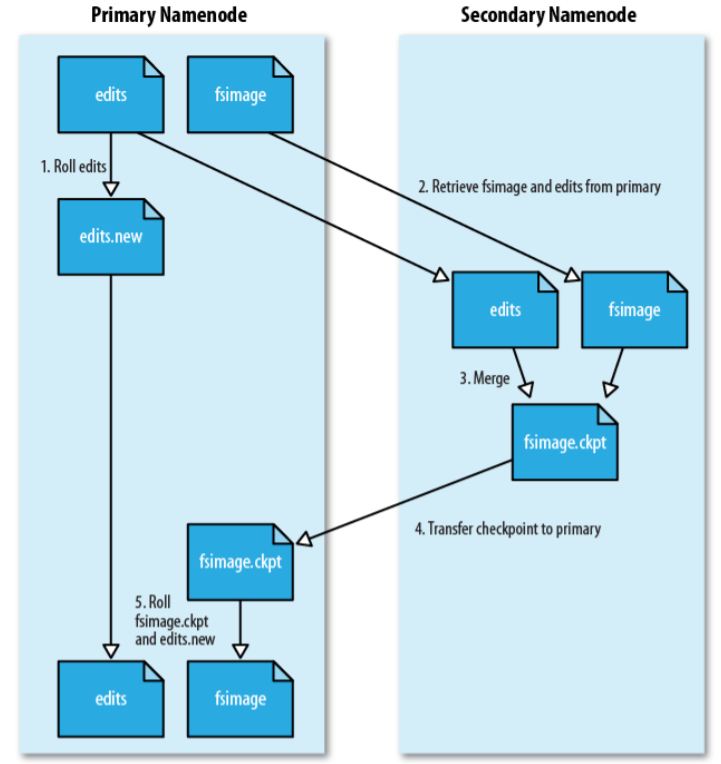
- SecondaryNameNode会定期和NameNode通信,请求其停止使用EditLog文件,暂时将新的写操作写到一个新的文件edit.new上来,这个操作是瞬间完成,上层写日志的函数完全感觉不到差别;
- SecondaryNameNode通过HTTP GET方式从NameNode上获取到FsImage和EditLog文件,并下载到本地的相应目录下;
- SecondaryNameNode将下载下来的FsImage载入到内存,然后一条一条地执行EditLog文件中的各项更新操作,使得内存中的FsImage保持最新;这个过程就是EditLog和FsImage文件合并;
- SecondaryNameNode合并后通过post方式将新的FsImage文件发送到NameNode节点上;
- NameNode将从SecondaryNameNode接收到的新的FsImage替换旧的FsImage文件,同时将edit.new替换EditLog文件,通过这个过程EditLog就变小了。
DataNode(数据节点)
数据节点是分布式文件系统HDFS的工作节点,负责数据的存储和读取,会根据客户端或者是名称节点的调度来进行数据的存储和检索,并且向名称节点定期发送自己所存储的块的列表。
每个数据节点中的数据会被保存在各自节点的本地Linux文件系统中。
HDFS体系结构
体系概述
HDFS采用了主从(Master/Slave)结构模型,一个HDFS集群包括一个名称节点( NameNode)和若干个数据节点(DataNode)。
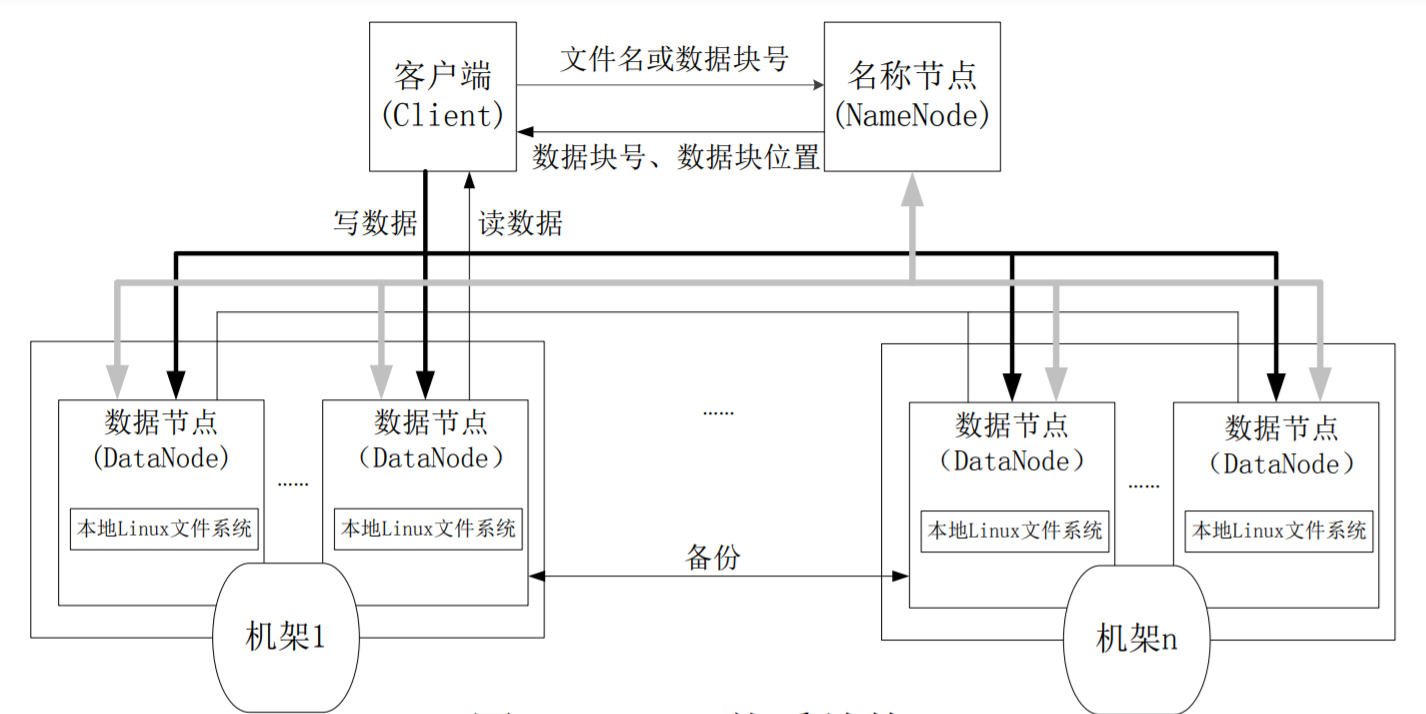
名称节点作为中心服务器,负责管理文件系统的命名空间及客户端对文件的访问。
集群中的数据节点一般是一个节点运行 一个数据节点进程,负责处理文件系统客户端的读/写请求,在名称节点的统一调度下进行数据块的创建、删除和复制等操作。
HDFS命名空间
HDFS的命名空间包含目录、文件和块。
在HDFS1.0体系结构中,在整个HDFS集群中只有一个命名空间,并且只有唯一一个名称节点,该节点负责对这个命名空间进行管理。
HDFS使用的是传统的分级文件体系。用户可以像使用普通文件系统一样,创建、删除目录和文件,在目录间转移文件,重命名文件等,但还没有实现文件访问权限、硬连接和软连接等功能。
通信协议
所有的HDFS通信协议都是构建在TCP/IP协议基础之上的。
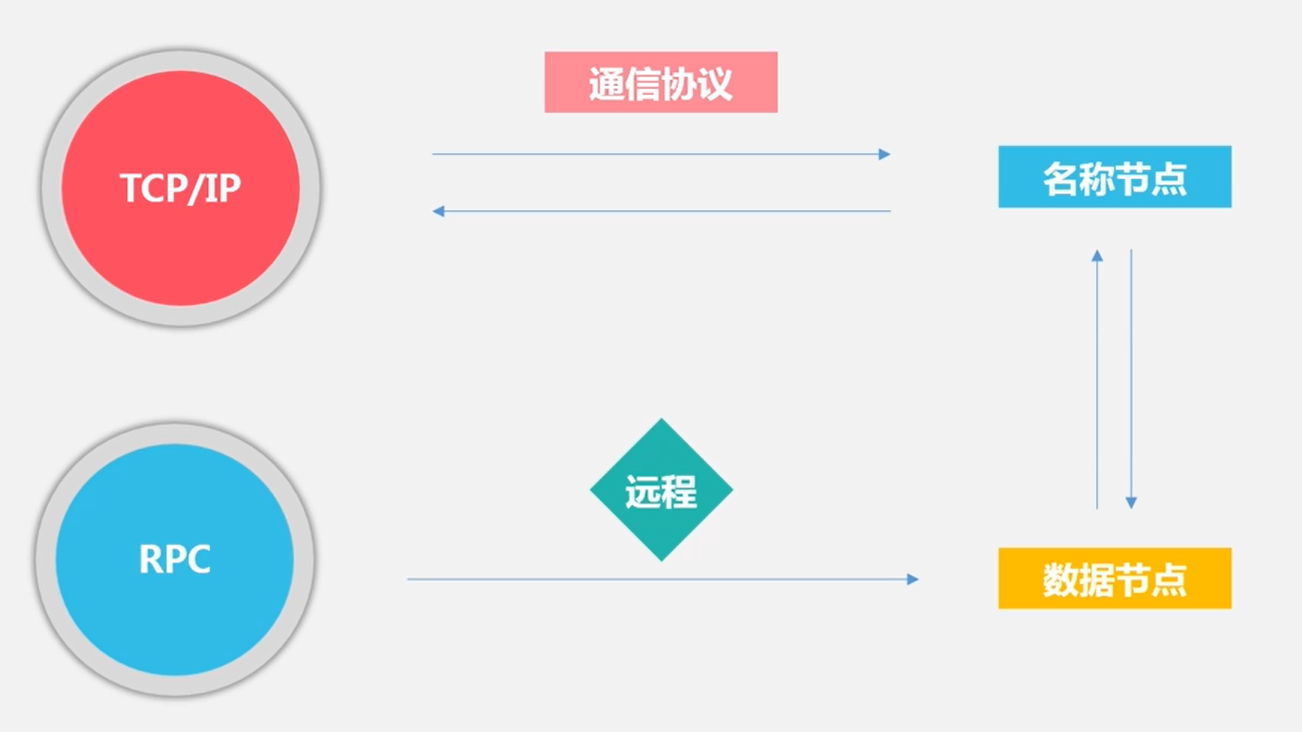
客户端通过一个可配置的端口向名称节点主动发起TCP连接,并使用客户端协议与名称节点进行交互。
名称节点和数据节点之间则使用数据节点协议进行交互。
客户端与数据节点的交互是通过RPC(Remote Procedure Call)来实现的。名称节点不会主动发起RPC,而是响应来自客户端和数据节点的RPC请求。
客户端
客户端是用户操作HDFS最常用的方式,HDFS在部署时都提供了客户端。HDFS客户端是一个库,暴露了HDFS文件系统接口。
严格来说,客户端并不算是HDFS的一部分。
- 提供类似Shell的命令行方式:访问HDFS中的数据客户端,支持打开、读取、写入等常见的操作
- 提供了Java API:应用程序访问文件系统的客户端编程接口
HDFS体系结构的局限性
原因:只设置唯一一个名称节点
- 命名空间的限制
- 性能的瓶颈
- 隔离问题
- 集群的可用性(单点故障问题)
SecondaryNameNode无法解决单点故障问题的原因:冷备份不是热备份(HDFS1.0的缺陷,在2.0中已经得到解决)
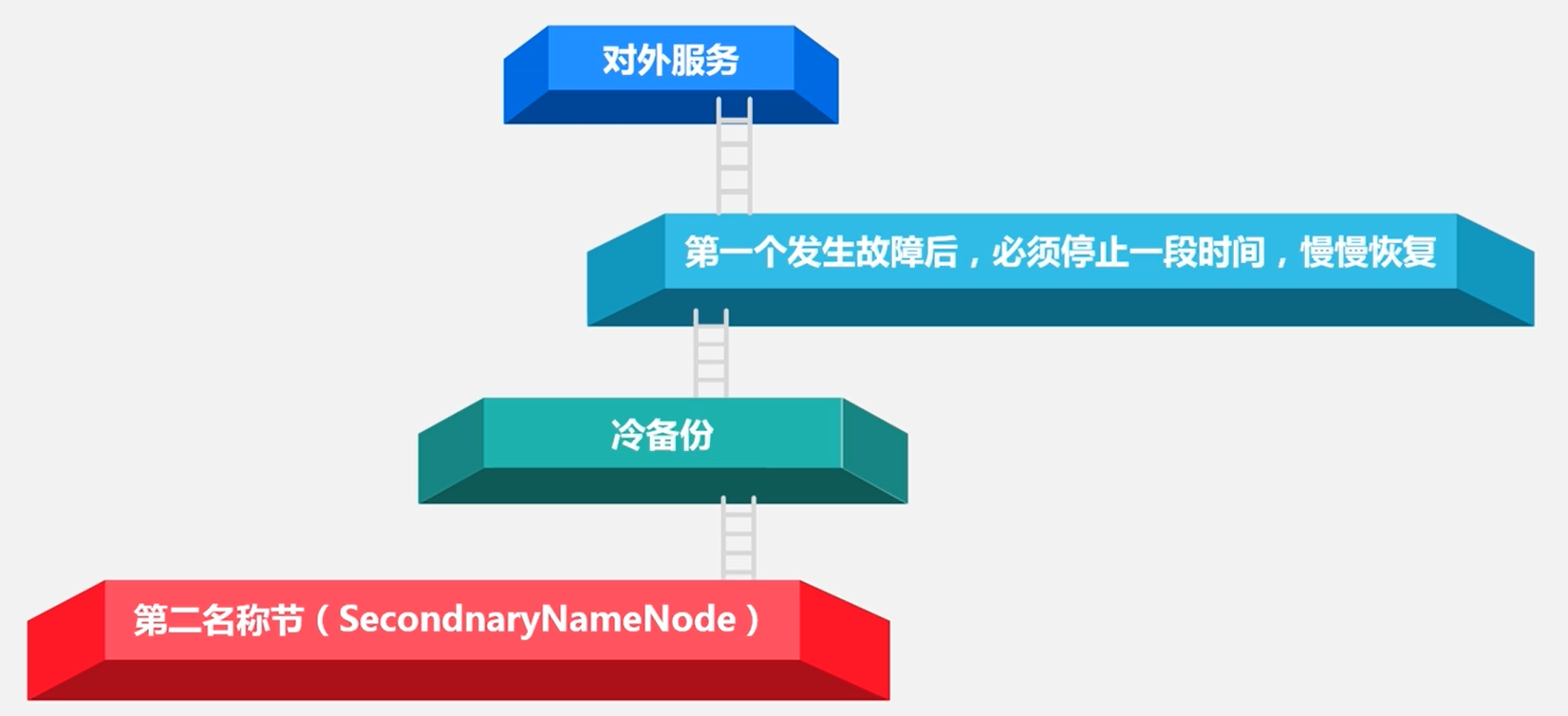
HDFS的存储原理
冗余数据保存
通常一个数据块的多个副本会被分布到不同的数据节点 上(默认值为3),优点:
- 加快数据传输速度
- 容易检查数据错误(互为备份,互为参照)
- 保证数据可靠性(冗余副本低于用户设定值,自动复制生成新副本)
数据存取策略
数据存放
一个HDFS集群通常包含多个机架,不同机架之间的数据通信通常需要经过交换机和路由器,同一个机架上的不同机器之间的通信则不需要。默认冗余复制因子是3。
- 第一个副本:放置在上传文件的数据节点;如果是集群外提交,则随机挑选一台磁盘不太满、CPU不太忙的节点
- 第二个副本:放置在与第一个副本不同的机架的节点上
- 第三个副本:与第一个副本相同机架的其他节点上
- 更多副本:随机节点
数据读取
- HDFS提供了一个API可以确定一个数据节点所属的机架ID,客户端也可以调用API获取自己所属的机架ID。
- 当客户端读取数据时,从名称节点获得数据块不同副本的存放位置列表,列表中包含了副本所在的数据节点,可以调用API来确定客户端和这些数据节点所属的机架ID,当发现某个数据块副本对应的机架ID和客户端对应的机架ID相同时,就优先选择该副本读取数据,如果没有发现,就随机选择一个副本读取数据。
数据复制
流水线复制的策略
数据错误与恢复
HDFS把硬件出错看作一种常态,而不是异常,并设计了相应的机制检测数据错误和进行自动恢复。
NameNode出错
最核心的两大数据结构FsImage和Editlog发生损坏,那么整个HDFS实例将失效。
HDFS1.0:暂停服务一段时间,SecondaryNameNode冷备份恢复。
HDFS2.0以后:热备份马上恢复。
DataNode出错
每个数据节点会定期向名称节点发送“心跳”信息,向名称节点报告自己的状态。
当数据节点发生故障,或者网络发生断网时,名称节点就无法收到来自一些数据节点的心跳信息,这时,这些数据节点就会被标记为“宕机”,节点上面的所有数据都会被标记为“不可读”,名称节点不会再给它们发送任何I/O请求。
名称节点会定期检查副本数量,一旦发现某个数据块的副本数量小于冗余因子,就会启动数据冗余复制,为它生成新的副本。
HDFS和其它分布式文件系统的最大区别就是可以调整冗余数据的位置(发生负载不均衡的时候同样可以调整)。
数据出错
检验数据出错:客户端在读取到数据后,会采用md5和sha1对数据块进行校验,以确定读取到正确的数据。
如果校验出错,客户端就会请求到另外一个数据节点读取该文件块,并且向名称节点报告这个文件块有错误,名称节点会定期检查并且重新复制这个块。
HDFS的数据读写过程
代码示例
读取文件代码:
1 | import java.io.BufferedReader; |
写入文件代码:
1 | import org.apache.hadoop.conf.Configuration; |
读取过程
相关的类:
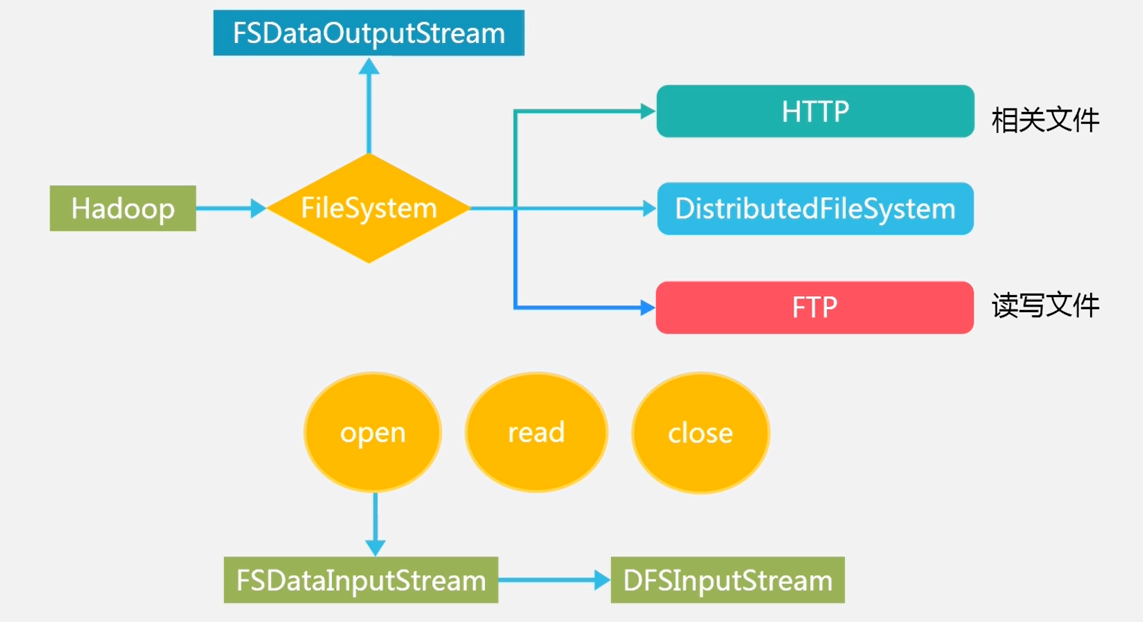
- FileSystem是一个通用文件系统的抽象基类,可以被分布式文件系统继承,所有可能使用Hadoop文件系统的代码,都要使用这个类。
- DistributedFileSystem是FileSystem在HDFS文件系统中的具体实现。
- FileSystem的open()方法返回的是一个输入流FSDataInputStream对象,在HDFS文件系统中具体的输入流为DFSInputStream;FileSystem中的create()方法返回的是一个输出流FSDataOutputStream对象,在HDFS文件系统具体的输出流为DFSOutputStream。
1 | Configuration conf = new Configuration(); //创建一个Configuration对象时,其构造方法会默认加载工程项目下两个配置文件:hdfs-site.xml和core-site.xml,这两个文件中包含访问HDFS所需的参数值(主要是fs.defaultFS,指定了HDFS的地址,有了这个地址客户端就可以通过这个地址访问HDFS了) |
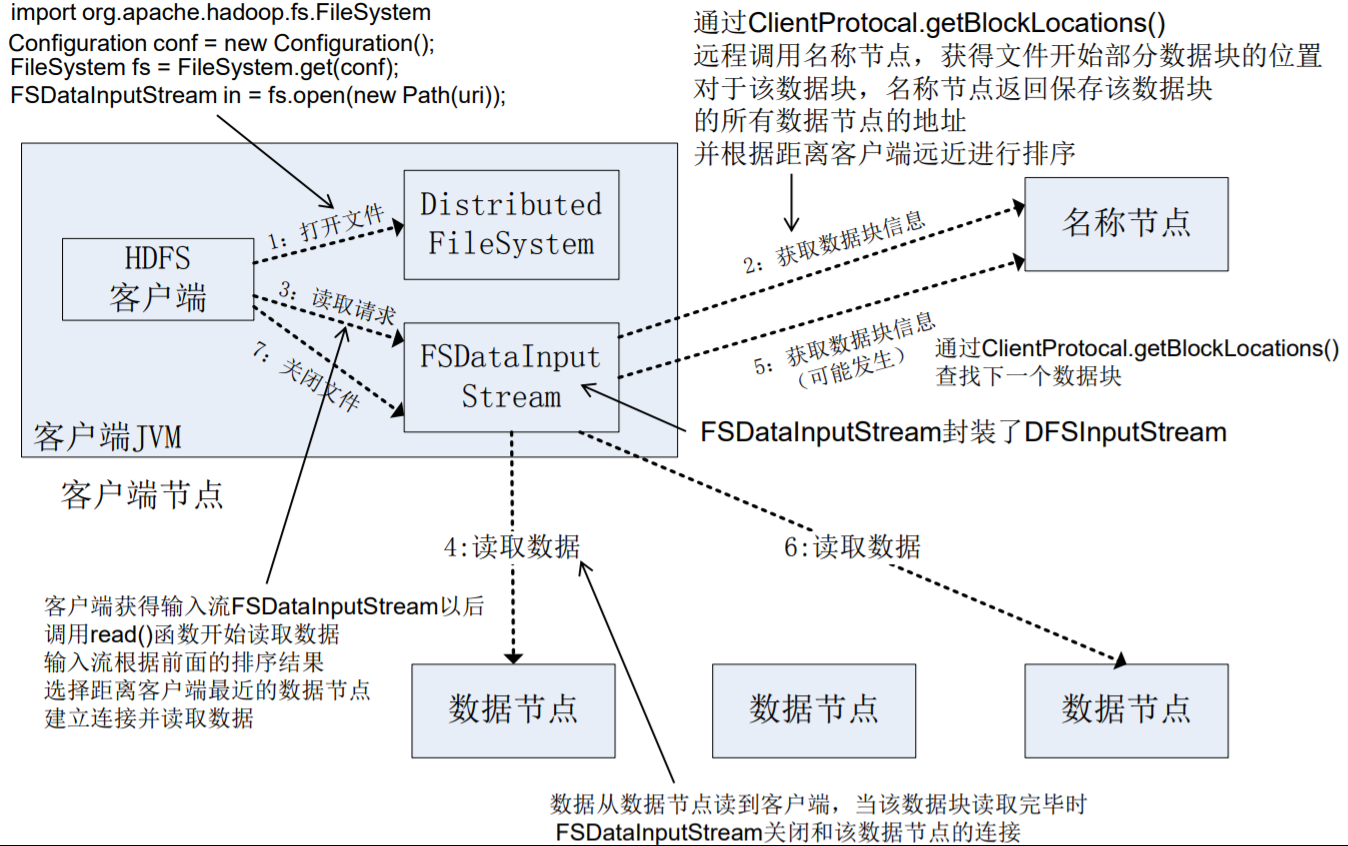
在读取数据过程中,若客户端与DataNode通信时出现错误,就会尝试连接包含此数据块的下一个DataNode。
写入过程
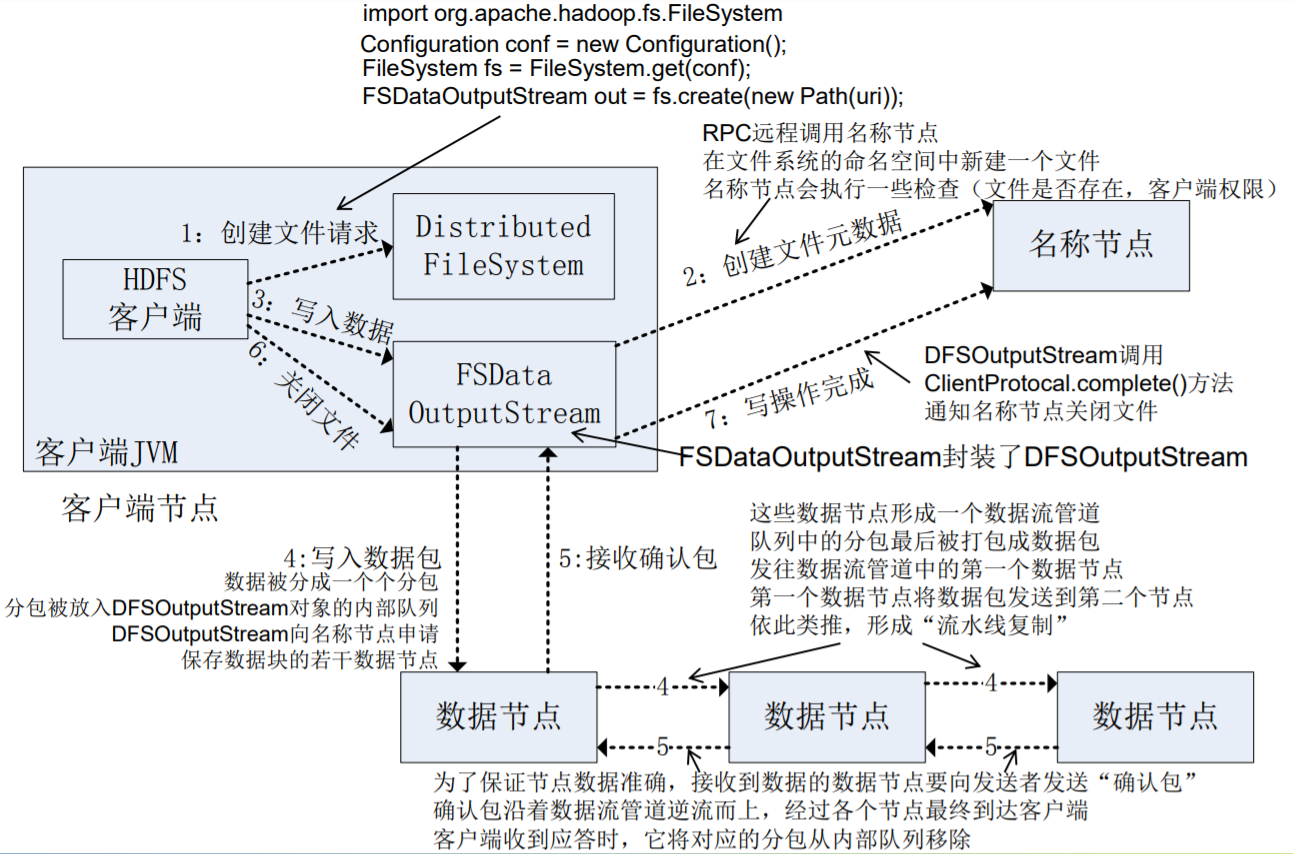
写入文件采用流水线复制策略,最终在每个DataNode中的数据内容都是一样的。
HDFS编程实践
实际上有三种shell命令方式:
1.hadoop fs
2.hadoop dfs
3.hdfs dfshadoop fs适用于任何不同的文件系统,比如本地文件系统和HDFS文件系统
hadoop dfs只能适用于HDFS文件系统
hdfs dfs跟hadoop dfs的命令作用一样,也只能适用于HDFS文件系统
统一格式:
1 | hadoop fs [genericOptions] [commandOptions] |
全部命令:
1 | [lpj@cpu-node0 ~]$ hadoop fs |