《大数据技术原理与应用》学习笔记——Ch2:大数据处理架构Hadoop
Intro
本文为《大数据技术原理与应用》第二章学习笔记。
Hadoop概述
“Hadoop”不是一个单一的技术,而是一系列大数据技术的结合体,是一整套解决方案的统称,可以称为一个项目。
两大核心:HDFS实现海量数据的分布式存储,MapReduce实现海量数据的分布式处理
特性:
- 高可靠性
- 高效性
- 高可扩展性
- 高容错性
- 成本低
- 运行在Linux平台上
- 支持多种编程语言
Hadoop生态系统
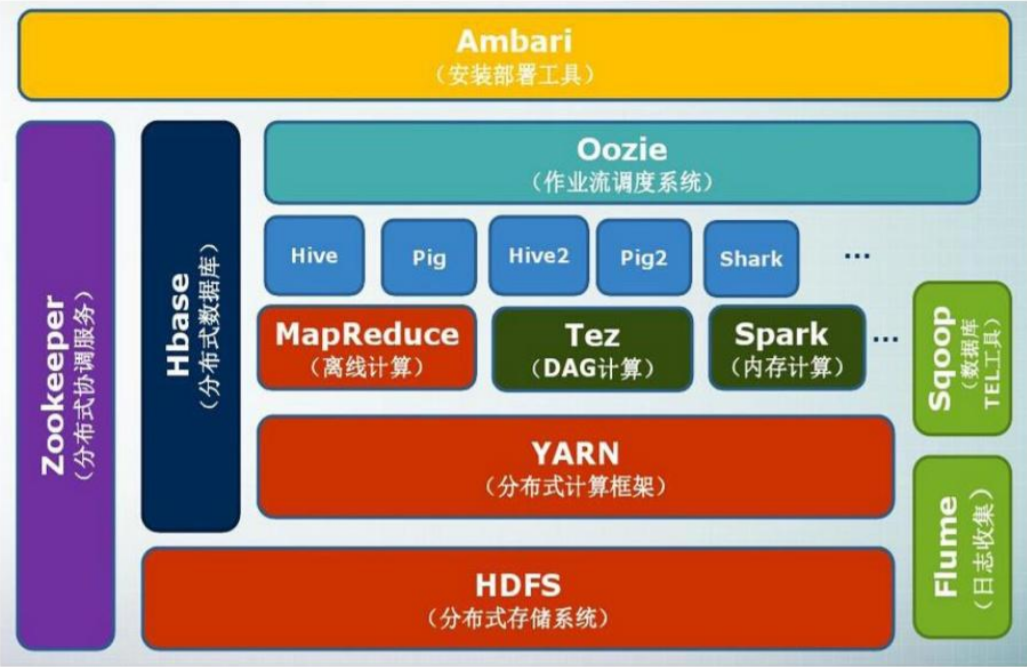
| 组件 | 功能 |
|---|---|
| HDFS | 分布式文件系统 |
| MapReduce | 分布式并行编程模型 |
| YARN | 资源管理和调度器 |
| Tez | 运行在YARN之上的下一代Hadoop查询处理框架 |
| Hive | Hadoop上的数据仓库 |
| HBase | Hadoop上的非关系型的分布式数据库 |
| Pig | 一个基于Hadoop的大规模数据分析平台,提供类似SQL的查询语言Pig Latin |
| Sqoop | 用于在Hadoop与传统数据库之间进行数据传递 |
| Oozie | Hadoop上的工作流管理系统 |
| Zookeeper | 提供分布式协调一致性服务 |
| Storm | 流计算框架 |
| Flume | 一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统 |
| Ambari | Hadoop快速部署工具,支持Apache Hadoop集群的供应、管理和监控 |
| Kafka | 一种高吞吐量的分布式发布订阅消息系统,可以处理消费者规模的网站中的所有动作流数据 |
| Spark | 类似于Hadoop MapReduce的通用并行框架 |
Hadoop的安装与使用
Hadoop基本安装配置主要包括以下几个步骤:
- 创建Hadoop用户
- SSH登录权限设置
- 安装Java环境
- 单机安装配置
- 伪分布式安装配置
配置SSH的原因: Hadoop名称节点(NameNode)需要启动集群中所有机器的Hadoop守护进程,这个过程需要通过SSH登录来实现。Hadoop并没有提供SSH输入密码登录的形式,因此,为了能够顺利登录每台机器,需要将所有机器配置为名称节点可以无密码登录它们。
单机&伪分布式安装参照:Hadoop3.1.3安装教程:单机&伪分布式配置
Hadoop集群的部署及使用
一个基本的Hadoop集群中的节点主要有:
HDFS:
- NameNode:负责协调集群中的数据存储
- DataNode:存储被拆分的数据块
- SecondaryNameNode:帮助NameNode收集文件系统运行的状态信息(冷备份)
MapReduce:
- JobTracker:协调数据计算任务
- TaskTracker:负责执行由JobTracker指派的任务
集群硬件配置:
DateNode:

NameNode:

相关推荐



评论
TwikooWaline

